

Dans le processus de digitalisation engagé par le secteur, la prégnance de la data vire à l’obsession. Mais les assureurs sont-ils vraiment prêts ? En dépit des grands discours, le marché semble loin d’être à la page.
Journaliste
Au centre du fameux « virage numérique » ou de la non-moins célèbre « transformation digitale », deux formules déjà usées jusqu’à la corde avant même d’avoir été mises en œuvre, l’enjeu crucial du futur des assureurs se résume finalement en quatre lettres : D.A.T.A.
Désormais, pas une stratégie sans évoquer le big data, pas une réunion sans parler de data scientist ou de data center, pas un communiqué officiel sans faire allusion au data mining… Il faut dire que les chiffres autour de la donnée donnent le tournis. Avec un marché du big data estimé en France à 652 M€ d’ici 2018 (contre 285 M€ en 2014 selon une étude IDC/HP), le secteur de la finance, et tout particulièrement l’assurance, n’est pas en reste. Près de la moitié des compagnies à travers le monde auraient déjà lancé des pilotes ou des projets analytics ou big data au cours de l’année 2015 selon Accenture, qui précise que 63 % des enseignes du secteur utilisent déjà les données issues du big data pour offrir des produits personnalisés. Quand on sait que la valeur des données personnelles en Europe atteint déjà plus de 300 Md€ et que les données liées à la géolocalisation récoltées par les prestataires de service sont évaluées à près de 100 Md€, les perspectives semblent florissantes.
« La data a toujours été la matière première des assureurs, notamment à travers le travail de tarification des contrats. Désormais, il y a une évolution de la chaîne de valeurs et de la mise à profit de ces données », explique Laurence Al Neimi, manager chez Solucom, practice banque & assurance. « La vision stratégique des assureurs met aujourd’hui la data au cœur de leur business model, qui, de fait, est révolutionné. »
Pour autant, le marché de l’assurance, notamment français, est-il vraiment armé pour utiliser au mieux cet afflux de données ? A-t-il vraiment les capacités financières, humaines et techniques ou encore le savoir-faire et les autorisations réglementaires, pour capter, trier et faire parler ce que d’aucuns appellent le « nouvel or noir » ?
« Dans le secteur de l’assurance, nous devons impérativement passer de la théorie à la pratique. Nous ne sommes pas loin du passage à l’acte, non pas de la récupération de la data car globalement cela se fait déjà, mais sur l’agrégation et la consolidation des données vers des tiers de confiance », fait remarquer Jean-Luc Gambey, co-organisateur du Hub-TDay Insurance (voir encadré). « Pour moi, le passage à l’acte est beaucoup plus avancé en Allemagne ou aux États-Unis. »
Législation tatillonne
D’abord, si tout le monde s’accorde à dire que le secteur fait preuve d’intérêt et de proactivité sur la question de la donnée, en ligne avec le plan « Réunir la nouvelle France industrielle » lancé par Emmanuel Macron pour créer 137 000 emplois liés au big data d’ici 2020, les assureurs se heurtent à une législation compliquée, voire tatillonne, autour de la gestion des données à caractère personnel.
La Cnil (Commission nationale de l’informatique et des libertés), qui veille déjà à l’application des règles pour encadrer les traitements de ces données personnelle avec un régime de sanctions en cas de non respect, souhaite davantage responsabiliser les entreprises. Ainsi, elle prône par exemple la mise en place d’un délégué à la protection des données, obligatoire pour le secteur public et pour les entreprises de plus de 250 salariés, mais aussi lorsque les activités exigent un suivi régulier et systématique des données personnelles.
Les compagnies doivent également faire face à un règlement qui se renforce hors des frontières. La Commission européenne, elle aussi très regardante sur la question, souhaite une plus grande harmonisation des règles de protection des données et une responsabilisation des entreprises. En outre, elle veut étendre par une directive spécifique l’application des règles de protection de la data au domaine de la coopération policière et judicaire.
« Les données de santé sont très encadrées et les assureurs sont contraints de respecter la règle du « privacy by design » afin de veiller à leur confidentialité. Ils n’ont pas le droit d’utiliser les données pour sélectionner ou surtarifer les clients sur la base de leur consommation médicale individuelle », précise Jean-Louis Delpérié, associé chez Exton Consulting. « Toutes les activités d’assurance sont aujourd’hui impactées par cette exploitation de la data avec des limites sur certaines branches. Sur la récupération et l’exploitation des données de santé par exemple, nous sommes encore loin de ce que font les Américains. Ici, les assureurs ne sont que des complémentaires, par conséquent tant que le régime obligatoire existera, il sera compliqué de collecter et de tirer profit de ces données de manière directe », poursuit Laurence Al Neimi.
Si certaines compagnies se lancent désormais sur le créneau du Pay How You Drive, à l’image d’Allianz ou de Direct assurance, qui devraient bientôt être suivis par la Maif ou Société générale Insurance, l’exploitation des flux de data récoltés auprès des conducteurs est encore sensible et soumise à bon nombre de contraintes. En France, les autorités planchent notamment sur le droit de tout un chacun de pouvoir accéder à ses données et les rectifier. « Actuellement, le cadre juridique autour de ces données n’est pas stabilisé, leur utilisation ne peut nuire au consommateur. Du côté des assureurs, cela permet d’avoir des éléments supplémentaires pour mieux personnaliser offres et services, mieux cibler les attentes, c’est le jeu de la concurrence », indique de son côté Maud Duval, directrice générale adjointe du groupe Matmut, en charge de l’organisation et des systèmes d’information.
Installations trop légères ?
Et dans ce jeu de la concurrence, ceux qui ne considèrent pas les réjouissances réglementaires comme des obstacles ont d’autres soucis, techniques cette fois-ci.
« Les assureurs sont conscients qu’il y a aujourd’hui beaucoup de données et il est encore très complexe pour eux de traiter tout leur potentiel. Les systèmes cœurs des compagnies, parfois vieillissants, sont encore trop peu agiles pour exploiter au mieux toutes ces informations », selon Laurence Al Neimi.
« On nous parle sans cesse de data center, de datalake flambant neufs ou de calculateurs dernière génération. Les assurés n’ont aucune idée du coût de ce type d’installations ! Nos propres centres de stockage datent de plus de dix ans, avec une cadence qui n’est plus suffisante », déplore sous couvert d’anonymat le responsable du service informatique d’un bancassureur. « On compare à juste titre la course à la data à celle du pétrole à la fin du 19e siècle aux États-Unis. On sait qu’il y en a tout autour de nous, mais on ne sait pas vraiment encore comment l’extraire, où la stocker et quoi en faire », fait remarquer l’actuaire d’un réassureur de la place. « Pour stocker puis utiliser correctement ces données, faire appel à des prestataires est aujourd’hui indispensable », enchaîne-t-il.
Car avant de pouvoir manipuler la data, la vraie question pour les assureurs réside aujourd’hui dans le fait de savoir qui est capable de gérer, stocker et condenser des flux de données gigantesques. Réponse : les datacenters. Mais encore faut-il avoir le budget et trouver une place dans ces centres de données dont l’image n’est pas toujours très bonne. Outre les questions de sécurité et de confidentialité des données, les datacenters sont très gourmands en énergie. D’après le Syndicat des entreprises du numérique en France (Syntec), un centre de 10 000 m2 consommerait autant qu’une ville de 50 000 habitants et près de 10 % de l’électricité tricolore serait engloutie par les 135 centres de données que compte le pays : pas vraiment en accord avec les politiques RSE instaurées par les compagnies de la place.
Qu’importe, les grands assureurs n’ont pas d’autre choix. Si des acteurs comme la Macif disposent de leurs propres installations (un premier datacenter mis en service en 2004 et un second en 2011), ou comme l’Agirc-Arrco, qui avec son propre centre à Gradignan (Gironde) gère les informations relatives à 19 millions de cotisations retraite, Generali France fait pour sa part appel à la société Equinix et son datacenter de Pantin (93).
Beaucoup de compagnies se sont adjointes les services d’Interxion qui gère sept datacenters en région parisienne et son dernier né « MRS1 » à Marseille. L’exploitant dispose des certifications ISO 27 001 et ISO 22 301, des normes de référence en matière de gestion de la sécurité de l’information, également appliquées aux banques et aux compagnies d’assurance pour leurs centres de données. Interxion vient d’ailleurs d’obtenir un agrément de l’Asip santé (Agence des systèmes d’information partagés de santé) qui l’autorise à héberger dans un environnement hautement sécurisé des données de santé à caractère personnel et d’en assurer la confidentialité et l’intégrité. De quoi rassurer ses clients. Autre opérateur apprécié des compagnies, l’entreprise DATA4 qui a récemment installé « un campus » de datacenters à Marcoussis (Essonne), l’Île-de-France accueillant aujourd’hui presque une cinquantaine de centres de données disséminés entre La Défense, la Seine-Saint-Denis ou la Seine-et-Marne, largement alimentés par les compagnies, IP ou mutuelles du marché.
« Certains assureurs sont attentifs aux autres clients qu’ils côtoient au sein des datacenters qu’ils choisissent. Des opérateurs téléphoniques ou des fournisseurs d’accès internet leur assurent des milliers de connexions et un certain gage de sérieux et de rapidité. C’est essentiel sur des transactions financières », précise notre actuaire. Toutefois, l’exemple de plusieurs compagnies étrangères pourrait faire des émules dans les années à venir, certains assureurs ayant franchi le pas en décidant d’exploiter leurs propres centres de données. C’est le cas du géant américain AllState à Rochelle (Illinois), de Travelers et son datacenter de 200 M$ baptisé « Project Oasis », ou encore de Liberty Mutual qui exploitera bientôt un centre géant à Frisco (Texas), le « Patronus Data Center », qui bénéficiera aussi à Toyota ou Fed Ex. La palme revient à China Life Insurance qui vient d’inaugurer au milieu de son siège social dernier cri à Pudong (dans la banlieue de Shanghai) un datacenter interne, ultramoderne, à l’image du plus gros assureur du pays.
Mais si posséder ou déléguer le bon support est une chose, correctement l’utiliser en est une autre. « La qualité de ces données est encore perfectible. À l’heure actuelle, la data enregistrée par les assureurs n’est pas toujours saisie de manière complète et homogène. Ces données sont mal ou différemment qualifiées selon les systèmes et, par conséquent, on ne maîtrise pas toujours leurs valeurs réelles au moment de l’analyse. Pour exemple, une donnée aussi essentielle que « prime d’assurance » peut être pure, totale, nette, brute, hors taxe, TTC ; si la définition des données n’est pas précisément définie, saisie et réconciliée, il y a un fort risque d’erreur dans la manipulation des informations », précise Laurence Al Neimi.
Ressources internes
Alors que la « règle des 3 V » propre au big data (volume, vitesse et variété) s’applique aujourd’hui à tous les secteurs qui opèrent leur mue digitale, les compagnies d’assurance y intègrent un quatrième V pour « valeur », avec une difficulté supplémentaire et non des moindres : trouver les ressources pour exploiter, lire et transformer cette data. SelonE&Y seules 6 % des grandes entreprises tricolores disposeraient aujourd’hui d’un effectif d’experts de la data supérieur à 50 personnes. Et les assureurs n’y coupent pas. « Pour l’heure, nous faisons plutôt appel à des sociétés externes, mais avec l’objectif de former nos collaborateurs déjà en charge aujourd’hui du traitement de données. Quoiqu’il en soit, nous avons déjà des ressources qui travaillent sur ces sujets et à l’avenir ces postes seront sans doute incontournables », indique Maud Duval. Si Société générale Insurance dispose déjà d’une équipe de data scientists qui planchent sur ces sujets prospectifs, peu d’enseignes ont par exemple un Chief Data Officer (CDO) ou des collaborateurs formés et totalement dédiés à ces données.
« Nous avons besoin de recruter des compétences extérieures nouvelles, sur des métiers que l’on n’avait pas forcément en interne. Dans le domaine du digital, nous avons aussi recruté une nouvelle génération, des gens très jeunes, y compris à des postes assez élevés », explique Pascal Demurger, directeur général de la Maif, qui a décidé en janvier dernier d’organiser un « Data Day » en interne pour sensibiliser ses collaborateurs à ces changements.
« Mais en même temps, il serait malsain de confier le digital et cette rupture uniquement à des gens venus de l’extérieur. D’abord, parce qu’il y a une culture d’entreprise à préserver, ensuite parce que tout le corps social sera embarqué par le digital, que ce soit à travers les outils ou les modes de pensée. Il y a donc une alchimie indispensable entre la permanence de la culture d’entreprise et la capacité d’y intégrer des nouveautés », poursuit-il.
« Au sujet des ressources pour traiter cette data, le groupe Matmut n’a pas encore d’opinion tranchée en la matière. Pour l’heure, nous sommes plutôt orientés vers des sociétés ou des start-up spécialisées qui nous aident à comprendre les impacts liés à l’utilisation des nouvelles solutions d’analyse de toute cette masse d’informations », ajoute de son côté Maud Duval.
Pourtant, les compagnies françaises semblent très impliquées quant à la réflexion et la formation de ces futurs spécialistes de la donnée. En partenariat avec l’Institut des actuaires, CNP assurances avait dès 2013 lancé un laboratoire de data science. L’année suivante, Axa et son Data Innovation Lab, un centreR&Dbig data, s’emparait aussi du sujet, avant d’ouvrir un second centre à Singapour avec des ressources dédiées à l’exploitation de ces données. Covéa s’est lui aussi doté d’un data lab expérimental fin 2015.
« En termes de formation autour de ces données, la France est très bien positionnée et très concernée. Le gouvernement cherche à utiliser le levier de la data comme source de réindustrialisation du pays. L’Institut des actuaires ou Télécom ParisTech proposent par exemple des formations autour de ces données, et nous bénéficions en France d’un bon taux d’équipement en la matière », précise-t-on chez Solucom.
Dernièrement, l’ESILV (Ecole supérieure d’ingénieurs Léonard de Vinci) de La Défense a par exemple annoncé qu’elle proposerait désormais un mastère spécialisé (MS) assurance, actuariat et big data pour former de futurs data scientists et data analysts, tout comme l’EPA (École polytechnique d’assurances) qui lancera en septembre 2016 un Executive MBA « data scientist des métiers de l’assurance ».
L’extrême limite
Devant cette manne impressionnante de data, d’autres problèmes, plus structurels pointent également le bout de leur nez, obligeant les assureurs à avancer encore plus à tâtons sur un sujet qu’ils ne maitrisent déjà pas correctement. C’est notamment le cas de la data émanant de l’Internet des objets (ou IoT : voir schéma).
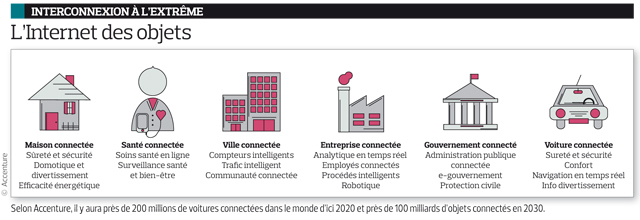
« Les technologies de l’IoT font partie des priorités d’investissements pour les assureurs. Elles leur offrent une abondance de données sur les comportements et les préférences des consommateurs. Les assureurs qui sauront capitaliser sur cette nouvelle manne d’information se créeront un avantage concurrentiel leur permettant d’offrir des services hautement personnalisés », indique Jean-François Gasc, directeur exécutif chez Accenture Strategy. Une course à la personnalisation qui n’est pas sans conséquences. « Il faut structurer correctement cette donnée pour ne pas créer de trouble sur le marché de l’assurance. Pour ce faire, il faut trouver un équilibre entre segmentation /personnalisation et mutualisation. Cela passe probablement par un rééquilibrage du processus de mutualisation des risques, note Jean-Luc Gambey. L’utilisation de ces données et des outils associés peut parfois provoquer un risque de désintermédiation et casser la chaîne traditionnelle de distribution de l’assurance » (voir regards croisés).
Autre composante importante, beaucoup de sinistres sont constatés à cause des données. « Trop de gens font une confiance aveugle en leur GPS. Les cas de décès de personnes perdues dans le désert à cause de leur GPS, notamment aux USA, restent élevés. Il y a également un problème de temporalité de toutes ces données », notait Charles Nepote, fondateur de l’Infolab et invité du « Data Day » Maif. Pour certains, la transformation numérique même à grande échelle ne passe donc pas uniquement par la data. « Lorsque nous pensons digital, nous ne sommes pas uniquement focalisés sur le sujet data. Si d’autres compagnies ont fait le choix d’être « data driven », nous pensons que la data est incontournable dans nos métiers, mais que ce n’est pas l’alpha et l’omega du digital, note Pascal Demurger. Dans l’acculturation du corps social de la Maif au sujet du digital, nous prenons ce virage avec de nombreuses autres composantes que sont les offres produits, l’expérience client ou la culture interne par exemple » (voir trois questions à).
« Le seul « bémol » à cette exploitation de la data, c’est lorsque l’individu va prendre conscience de la valeur de ses données personnelles. Pour l’heure, on le pille sans qu’il s’en rende vraiment compte, mais lorsqu’il va comprendre que sa data (navigation, santé, comportementale, etc.) lui appartient, la donne va changer, prévient Jean-Luc Gambey. Soit il mettra un frein à la capture, au pillage de ses données, soit il monétisera sa data à un assureur ou un intervenant X ou Y. Ce phénomène pourrait avoir du sens et révolutionner les modalités d’achat (comme le fait déjà l’entreprise Datacoup.com) si une masse d’individus suit ce mouvement. »
Au final, si les assureurs semblent alertes sur le sujet de la data, ils doivent acquérir une véritable agilité pour en tirer une réelle valeur ajoutée, pour eux, mais aussi pour leurs clients.
En retour, ils devront faire face à une nouvelle concurrence venue d’acteurs étrangers au secteur (les fameux GAFA) pour qui la data n’a déjà plus de secrets.
Quand on sait que les données numériques créées dans le monde s’élèveront à 40 zettaoctets (1021 octets) en 2020, voire au yottaoctet (1 024 octets) dans moins de trente ans, les compagnies doivent encore accélérer sur la question.
Certains comme Andrew Ellis, chercheur à l’université Aston de Birmingham, prédisent déjà l’explosion d’Internet à cause d’une masse trop importante de data sur la Toile d’ici 2023.



